

Build a Pseudocode to Python Converter API
In this post, we will create a script that will convert pseudocode into Python executable code. We'll learn about string manipulation and Django.

What did Pseudo say to Python? "Bibbidi-bobbidi-boo"
~ Laptop and the Fairy Lady
In this article, we will create a script that will convert pseudocode into Python executable code. Along the way, we'll learn about string manipulation and become more acquainted with regular expressions.
This article was written as a fun weekend project. To get the most out of this article, you should be familiar with regular expressions or be willing to practice while we code. This tutorial project's Github repository can be found here.
Prerequisite
- Regular Expression
- Django
- Django Rest Framework
What is a Pseudocode?
Pseudocode is an algorithm representation that is more similar to human language than computer machine code. To be honest, converting from Pseudocode to Python feels almost identical to converting from Python to any other non-machine code programming language. All of them represent a type of algorithm or procedure that the machine executes.
Psuedocodes are convertible to Python because they, like Python and any other programming language, have some structure or reserved keywords. Some examples are "BEGIN," "DECLARE," "START," "STOP," "SET," "GET," and so on.
A pseudocode is demonstrated here:
DECLARE String user_name;
DECLARE Character first_name;
DECLARE Integer current_index;
SET user_name = "vibes-driven-dev";
SET first_name = "I";
SET currentIndex = 0;
WHILE currentIndex < 5;
DISPLAY "My real name is Ifenna and it starts with the letter: " + first_name;
SET currentIndex = currentIndex + 1;
ENDWHILE;
IF currentIndex >= 5:
DISPLAY "Just kidding call me The " + user_name;
ENDIF;
The WHILE loop in the preceding pseudocode simply repeats the content of 'DISPLAY' if the currentIndex integer is less than 5. When the currentIndex value is greater than or equal to 5, the IF loop displays the text. Really, it's just a dumb pseudocode that consumes memory for no apparent reason, but you get the point.
How should we approach this project?
We can use the fact that there is some structure to how pseudocodes are designed to our advantage. Let's take a look at the above code in Python.
user_name = "vibes-driven-dev"
first_name = "I"
currentIndex = 0
while currentIndex < 5:
print("My real name is Ifenna and it starts with the letter: ", first_name)
currentIndex = currentIndex + 1
if currentIndex >= 5:
print("Just kidding call me The ", user_name)
It's not the most Pythonic code, but it'll suffice for now. The similarities between the two examples are obvious. We can disregard the first few lines with the DECLARE words because we know that we typically do not declare or initialize variables before assigning them in Python.
Nevertheless, we can take advantage of that by noting all the variables and the types that have been assigned to them. We have STRING, CHARACTER, and INTEGER in the pseudocode example. In order to prevent errors caused by Type errors, we can keep track of these. Consider the comparison of a string and an integer, currentIndex <= first_name.
Aside from the variable types, we should also note the use of semicolons. In Pseudocodes, semicolons are also optional. Additionally, there are times when a statement in the pseudocode is incorrect. For instance:
DECLARE BadGuyVariableType user_name;
DECLARE Character first_name;
DECLARE Integer current_index;
We will eventually keep track of an invalid variable type called "BadGuyVariableType" if there are no checks. To check for invalid patterns, we'll use regular expressions (RegEx). If you are unfamiliar with RegEx, kindly brush up on it.
The elephant in the room, of course, is the indentations we use in Python.
Pseudocode and Python code comparison
We can conclude the following after comparing the Pseudocode and Python code from the preceding section:
- "DECLARE [VARIABLE TYPE]" will be removed/ignored, but we will make sure to track the variable and its type.
- "DECLARE [VARIABLE TYPE]" will go through a variable type check to prevent invalid type usage.
- "SET" will be removed but the values following will be kept
- "DISPLAY [STRING CONTENT]" will change to "print([STRING CONTENT])"
- "DISPLAY [STRING CONTENT] + [VARIABLE/STRING]" will replace "+" with ","
- "WHILE" and "IF" will require that the indentation level be tracked.
How can the indentation be tracked?
We'll be using string manipulation. Simply multiplying spaces/tabs by the level of indentation. As an illustration:
empty_string = ""
print(empty_string * 2) # returns empty.
single_space = " "
print(single_space * 2) # returns two spaces (" ")
single_tab = " "
print(single_tab * 2) # returns two tabs which is approximately 8 spaces (" ")
The indentation level is represented by "2" in the example above. Assume we come across an IF/ELSE block in the first level (level 1); the value encapsulated in the IF/ELSE block will naturally fall into the second level (level 2). The code snippet below demonstrates a simple example:
if True: # initial level (level 1)
print("My spirit animal is a mosquito") # second level (level 2) within the IF block
else: # back to initial level (level 1)
print("My spirit animal is a slug") # back to second level because this is an ELSE block
if "stress": # Still on the 2nd level
print("This is a 3rd level indentation because it's in a IF block inside an ELSE block")
I hope that clarifies what "indentation level" means. Because there are ENDIF and ENDWHILE statements to indicate the end of a block level, we will be able to track these levels. Therefore, whenever we encounter a line with WHILE/IF/ELSE/ELIF and ENDWHILE/ENDIF, respectively, we will increase or decrease the indentation levels.
Creating the pseudocode converter script from scratch
In the terminal, we create a file called "pseudopy.py."
echo > pseudopy.py
To assess our progress in developing the pseudocode converter, we can refer back to the simplistic pseudocode example from earlier.
ex1 = """
DECLARE String user_name;
DECLARE Character first_name;
DECLARE Integer current_index;
SET user_name = "vibes-driven-dev";
SET first_name = "I";
SET currentIndex = 0;
WHILE currentIndex < 5;
DISPLAY "My real name is Ifenna and it starts with the letter: " + first_name;
SET currentIndex = currentIndex + 1;
ENDWHILE;
IF currentIndex >= 5:
DISPLAY "Just kidding call me The " + user_name;
ENDIF;
"""
ex2 = """
DECLARE String user_name;
DECLARE Character first_name;
DECLARE Integer current_index;
"""
ex3 = """
DECLARE String user_name;
DECLARE Character first_name;
DECLARE Integer current_index;
SET user_name = "vibes-driven-dev";
SET first_name = "I";
SET currentIndex = 0;
"""
We preprocess each line of text. To begin, we must divide the string into a list, with each pseudocode statement in its own string. We will remove whitespace from each line of the string list. We also remove any empty lines. As shown in the code below.
...
user_input = ex3
pseudo_no_empty_strings = list(filter(None, user_input.splitlines()))
print("pseudo_no_empty_strings") # remove this if you want
Testing our current code, in terminal:
[
'DECLARE String user_name;',
'DECLARE Character first_name;',
'DECLARE Integer current_index;',
'SET user_name = "vibes-driven-dev";',
'SET first_name = "I";',
'SET currentIndex = 0;',
'WHILE currentIndex < 5;',
'DISPLAY "My real name is Ifenna and it starts with the letter: " + first_name;', 'SET currentIndex = currentIndex + 1;',
'ENDWHILE;',
'IF currentIndex >= 5:',
'DISPLAY "Just kidding call me The " + user_name;',
'ENDIF;'
]
The results will remain the same even if we run the test using a \n (newline) in place of spaces.
We can still see that everything is almost the same and that the semicolons at the end have not been removed.
Let's address the issues related to each sentence or statement. Recall our surmise from comparing the Pseudocode and Python code, we have to figure out the "DECLARE [VARIABLE TYPE] [VARIABLE NAME]" statement. To do this, we introduce RegEx. The RegEx package has a flag (similar to case-insensitive) called re.VERBOSE that ignores spaces and allows us add comments inside our RegEx pattern. We will be using the re.compile, re.Pattern.match, re.sub and re.Match.group extensively for our string matching and manipulation.
In our script, add the following:
import re
ex1 = ...
...
...
re_flags = re.VERBOSE
# regex for DECLARE [VARIABLE TYPE] [VARIABLE NAME]
re_first_construct = re.compile(
"""
DECLARE # Start of DECLARE statement
\s* ( \w+ ) # Type
\s+ ( \w+ )(?: \s* )? # Variable name
\s* """,
re_flags,
)
We can test the pattern in a different python interactive terminal as seen below:
python
import re
re_flags = re.VERBOSE
a = 'DECLARE String user_name;'
b = 'nothing to declare'
re_first_construct = re.compile(
"""
DECLARE # Start of DECLARE statement
\s* ( \w+ ) # Type
\s+ ( \w+ )(?: \s* )? # Variable name
\s* """,
re_flags,
)
re_first_construct.match(a).groups()
# returns ('String', 'user_name')
re_first_construct.match(b).groups()
# returns AttributeError: 'NoneType' object has no attribute 'groups'
# this is because b variable has not "DECLARE" value at the start.
Instead of repeatedly writing "DECLARE," what if we wanted to allow multiple statement declarations on a single line? As an illustration, we want it to be something like DECLARE String user name, Char first name.
We can expand our pattern to look for values in the DECLARE statement that come after the comma (,). Add the following to our Python script:
re_flags = re.VERBOSE
# regex for DECLARE [VARIABLE TYPE] [VARIABLE NAME]
re_first_construct = re.compile(
"""
DECLARE # Start of DECLARE statement
\s* ( \w+ ) # Type
\s+ ( \w+ )(?: \s* )? # Variable name
\s* """,
re_flags,
)
re_remainder = re.compile(""" \s* ( \w+ )(?: \s* \[ \s* \] )? \s* """, re_flags) # <-- NEW
re_remainder matches the patterns that appear after the comma in the DECLARE statement ("DECLARE [VARIABLE TYPE] [VARIABLE NAME]"), such that ", [VARIABLE TYPE] [VARIABLE NAME], [VARIABLE TYPE] [VARIABLE NAME]". The follow-up variables essentially look like this:
"re_first_construct(DECLARE [VARIABLE TYPE] [VARIABLE NAME]), re_remainder([VARIABLE TYPE] [VARIABLE NAME], [VARIABLE TYPE] [VARIABLE NAME])"
Remember that keeping track of variable types is necessary to prevent TypeErrors brought on by unsupported operations between instances of various types. In order to keep track of variables and their types, we add a Python dictionary. However, we could hardcode the list of variable types as a constant or variable to ensure that we do not allow incorrect variable types like "BadGuyVariableType".
import re
ex1 = ...
...
...
TYPES = {. # <----NEW
"integer": "int",
"double": "float",
"float": "float",
"boolean": "bool",
"character": "str",
"string": "str",
}
re_flags = re.VERBOSE
# regex for DECLARE [VARIABLE TYPE] [VARIABLE NAME]
re_first_construct = re.compile(
"""
DECLARE # Start of DECLARE statement
\s* ( \w+ ) # Type
\s+ ( \w+ )(?: \s* )? # Variable name
\s* """,
re_flags,
)
re_remainder = re.compile(""" \s* ( \w+ )(?: \s* \[ \s* \] )? \s* """, re_flags)
var_types = {} # NEW
Let's loop through the items on our list that don't have any empty strings or whitespace. At the end of each line of pseudocode, we remove any semicolons or colons.
...
...
re_remainder = re.compile(""" \s* ( \w+ )(?: \s* \[ \s* \] )? \s* """, re_flags)
var_types = {}
for codeline, line in enumerate(pseudo_no_empty_strings, start=1):
line = re.sub("\s*[;:]\s*$", "", line) # <--- NEW
print(line) # Just to see how it looks now.
# Notice no more ";" or ":" on each line.
# You can delete this print() after confirming.
To be able to raise any errors on the precise line they occur, we are keeping track of the pseudocode line (codeline). The Python interpreter notifies us of any runtime errors in our code in a manner similar to this. Of course, you have the option of not checking, but keeping it will help you identify potential problem areas.
We'll loop through the pseudocode and look for any code lines that begin with the DECLARE statement. The variable type associated with each declared variable name can then be tracked in this way.
for codeline, line in enumerate(pseudo_no_empty_strings, start=1):
line = re.sub("\s*[;:]\s*$", "", line)
if line.startswith("DECLARE"):
var_type, first_var = re_first_construct.match(first_word).groups()
for varName in [first_var]:
if var_type.lower() not in TYPES.keys():
print(f"Line {codeline}: Unknown variable type '{var_type}'")
print("Expected variable type in: ", list(TYPES.keys()))
exit(1)
var_types[varName] = TYPES[var_type.lower()]
The above code will work for "DECLARE [VARIABLE TYPE] [VARIABLE NAME]" but not "DECLARE [VARIABLE TYPE] [VARIABLE NAME], [OTHER VARIABLE TYPE] [OTHER VARIABLE NAME]". In order to accommodate more declared variables, the FOR loop needs to be updated. Our script is updated as follows:
for codeline, line in enumerate(pseudo_no_empty_strings, start=1):
line = re.sub("\s*[;:]\s*$", "", line)
if line.startswith("DECLARE"):
first_word, *args = line.split(",") # NEW
var_type, first_var = re_first_construct.match(first_word).groups()
extra_vars = list(map(lambda x: re_remainder.match(x).groups()[0], args)) # NEW
for varName in [first_var] + extra_vars:
if var_type.lower() not in TYPES.keys():
print(f"Line {codeline}: Unknown variable type '{var_type}'")
print("Expected variable type in: ", list(TYPES.keys()))
exit(1)
var_types[varName] = TYPES[var_type.lower()]
The preprocessed pseudocode needs to be stored somewhere. Update the Python script with the following:
var_types: dict = {}
preprocessed_pseudocode = [] # <--- NEW
for codeline, line in enumerate(pseudo_no_empty_strings, start=1):
line = re.sub("\s*[;:]\s*$", "", line)
if line.startswith("DECLARE"):
first_word, *args = line.split(",")
var_type, first_var = re_first_construct.match(first_word).groups()
extra_vars = list(map(lambda x: re_remainder.match(x).groups()[0], args))
for varName in [first_var] + extra_vars:
if var_type.lower() not in TYPES.keys():
print(f"Line {codeline}: Unknown variable type '{var_type}'")
print("Expected variable type in: ", list(TYPES.keys()))
exit(1)
var_types[varName] = TYPES[var_type.lower()]
preprocessed_psuedocode.append(line) # <--- NEW
print(preprocessed_psuedocode) # Remove this line if you want after sanity check
The next step can now be taken since we have figured out the DECLARE statement and trailing punctuation. We must define the cases for each pseudocode construct (SET, DISPLAY and so on). Remember from the comparison of Pseudocode and Python:
- "DECLARE [VARIABLE TYPE]" will be removed/ignored
- "SET" will be removed but the values following will be kept
- "DISPLAY [STRING CONTENT]" will change to "print([STRING CONTENT])"
- "DISPLAY [STRING CONTENT] + [VARIABLE/STRING]" will replace "+" with ","
The logic for the pseudopy.py file is coded as follows in a new for-loop that iterates through the preprocessed pseudocode list:
output = []
for codeline, line in enumerate(preprocessed_pseudocode, start=1):
if (
line.startswith("DECLARE")
or line.startswith("PROGRAM")
or line.startswith("START")
or line.startswith("BEGIN")
):
output = []
elif line.startswith("DISPLAY"):
line = re.sub("DISPLAY ?", "print(", line).strip() + ")"
line = re.sub('("[^"]*?")\s*\+\s*', "\\1, ", line) # removes "+"
output = re.sub('\s*\+\s*("[^"]*?")', ", \\1", line)
elif line.startswith("SET"):
output = line.replace("SET", "").strip()
if not isinstance(output, list):
output = [output]
print(list(output)) # <----Sanity check. Remove this line if you want
Running the above script in your terminal results to:
['']
['']
['']
['user_name = "vibes-driven-dev"']
['first_name = "I"']
['currentIndex = 0']
We have successfully handled point 1, 3, 4, and 5. Now we can focus on point 6.
- "WHILE" and "IF" will require that the indentation level be tracked.
For the above statement to be fulfilled, we need to track the indentation levels of both WHILE and IF loops.
ex1 = ...
...
user_input = ex1 # <---- Updated to test the pseudocode with IF/WHILE
output = []
while_level = 0 # NEW
if_level = 0 # NEW
for codeline, line in enumerate(preprocessed_pseudocode, start=1):
if (
line.startswith("DECLARE")
or line.startswith("PROGRAM")
or line.startswith("START")
or line.startswith("BEGIN")
):
output = []
elif line.startswith("DISPLAY"):
line = re.sub("DISPLAY ?", "print(", line).strip() + ")"
line = re.sub('("[^"]*?")\s*\+\s*', "\\1, ", line) # removes "+"
output = re.sub('\s*\+\s*("[^"]*?")', ", \\1", line)
elif line.startswith("SET"):
output = line.replace("SET", "").strip()
elif line.startswith("WHILE"): # <----NEW
while_level += 1
output = line.replace("WHILE", "while").strip() + ":"
elif line.startswith("IF"): # <----NEW
if_level += 1
output = line.replace("IF", "if").strip() + ":"
if not isinstance(output, list):
output = [output]
print(list(output)) # <----Sanity check. Remove this line if you want
In our terminal, we can perform sanity check.
['']
['']
['']
['user_name = "vibes-driven-dev"']
['first_name = "I"']
['currentIndex = 0']
['while currentIndex < 5:']
['print("My real name is Ifenna and it starts with the letter: ", first_name)']
['currentIndex = currentIndex + 1']
['if currentIndex >= 5:']
['print("Just kidding call me The ", user_name)']
WHILE/IF are now lowercase and have semicolons at the end of the string. Let's add the logic for ENDWHILE/ENDIF to the code.
ex1 = ...
...
user_input = ex1 # <---- Updated to test the pseudocode with IF/WHILE
output = []
while_level = 0
if_level = 0
for codeline, line in enumerate(preprocessed_pseudocode, start=1):
indent_level = if_level + while_level #<---- NEW
if (
line.startswith("DECLARE")
or line.startswith("PROGRAM")
or line.startswith("START")
or line.startswith("BEGIN")
):
output = []
elif line.startswith("DISPLAY"):
line = re.sub("DISPLAY ?", "print(", line).strip() + ")"
line = re.sub('("[^"]*?")\s*\+\s*', "\\1, ", line) # removes "+"
output = re.sub('\s*\+\s*("[^"]*?")', ", \\1", line)
elif line.startswith("SET"):
output = line.replace("SET", "").strip()
elif line.startswith("WHILE"):
while_level += 1
output = line.replace("WHILE", "while").strip() + ":"
elif line.startswith("IF"):
if_level += 1
output = line.replace("IF", "if").strip() + ":"
elif line.startswith("ENDIF"): # <--- NEW
if if_level == 0:
print(f"line {codeline}: no IF block for ENDIF.")
exit(1)
if_level -= 1
output = ""
elif line.startswith("ENDWHILE"): # <--- NEW
if while_level == 0:
print(f"line {codeline}: no WHILE block for ENDWHILE.")
exit(1)
output = ""
while_level -= 1
if not isinstance(output, list):
output = [output]
print(list(output)) # <----Sanity check. Remove this line if you want
Quick sanity check in the terminal:
['']
['']
['']
['user_name = "vibes-driven-dev"']
['first_name = "I"']
['currentIndex = 0']
['while currentIndex < 5:']
['print("My real name is Ifenna and it starts with the letter: ", first_name)']
['currentIndex = currentIndex + 1']
['']
['if currentIndex >= 5:']
['print("Just kidding call me The ", user_name)']
['']
In addition to IF/WHILE, we have ELSE/ELIF. Let's update our code to take ELSE/ELIF into account. In cases where we are unable to determine the starting word, we provide a general error message.
ex1 = ...
...
user_input = ex1 # <---- Updated to test the pseudocode with IF/WHILE
output = []
while_level = 0
if_level = 0
for codeline, line in enumerate(preprocessed_pseudocode, start=1):
indent_level = if_level + while_level
if (
line.startswith("DECLARE")
or line.startswith("PROGRAM")
or line.startswith("START")
or line.startswith("BEGIN")
):
output = []
elif line.startswith("DISPLAY"):
line = re.sub("DISPLAY ?", "print(", line).strip() + ")"
line = re.sub('("[^"]*?")\s*\+\s*', "\\1, ", line) # removes "+"
output = re.sub('\s*\+\s*("[^"]*?")', ", \\1", line)
elif line.startswith("SET"):
output = line.replace("SET", "").strip()
elif line.startswith("WHILE"):
while_level += 1
output = line.replace("WHILE", "while").strip() + ":"
elif line.startswith("IF"):
if_level += 1
output = line.replace("IF", "if").strip() + ":"
elif line.startswith("ENDIF"):
if if_level == 0:
print(f"line {codeline}: no IF block for ENDIF.")
exit(1)
if_level -= 1
output = ""
elif line.startswith("ENDWHILE"):
if while_level == 0:
print(f"line {codeline}: no WHILE block for ENDWHILE.")
exit(1)
output = ""
while_level -= 1
elif line.startswith("ELSE"): # <--- NEW
if if_level == 0:
print(f"line {codeline}: ELSE with no preceding IF.")
exit(1)
output = "else:"
indent_level -= 1
elif line.startswith("ELIF"): # <--- NEW
if if_level == 0:
print(f"line {codeline}: no IF block for ELSEIF.")
exit(1)
output = line.replace("ELIF", "elif").strip() + ":"
indent_level -= 1
else: # <--- NEW
print(f'Error: line {codeline}: Cannot figure out: "{line.strip()}"')
exit(1)
if not isinstance(output, list):
output = [output]
print(list(output)) # <----Sanity check. Remove this line if you want
Now that we have everything, we must set up the appropriate indentation for each line. As seen below, we now store the newly converted Python code in a new list titled "converted pseudocode".
output = ""
while_level = 0
if_level = 0
converted_psuedocode = [] # <---NEW
for codeline, line in enumerate(preprocessed_pseudocode, start=1):
indent_level = while_level + if_level
if line.startwith(...):
...
...
indentation = indent_level * " " #<---- NEW
if not isinstance(output, list):
output = [output]
# Add indented python code line to the converted psuedocode list
# if the output python code is NOT an empty string
converted_psuedocode.extend(indentation + python_line for python_line in output if python_line != "")
# Sanity check dump into a python file
with open("sanity-check.py", "w") as python_file:
for python_output in converted_psuedocode:
python_file.write(python_output + "\n")
# print("---CONVERTED PSUEDOCODE SANITY CHECK---\n")
for python in converted_psuedocode:
print(python)
In the terminal,
user_name = "vibes-driven-dev"
first_name = "I"
currentIndex = 0
while currentIndex < 5:
print("My real name is Ifenna and it starts with the letter: ", first_name)
currentIndex = currentIndex + 1
if currentIndex >= 5:
print("Just kidding call me The ", user_name)
Yay, it works. Let's take a look at the following pseudocode example.
import re
ex4 = """
DECLARE String user_name;
DECLARE Character first_name;
DECLARE Integer current_index;
SET user_name = "vibes-driven-dev";
SET first_name = "I";
SET currentIndex = 0;
WHILE currentIndex < 5;
DISPLAY "My real name is Ifenna and it starts with the letter: " + first_name;
SET currentIndex = currentIndex + 1;
END WHILE;
IF currentIndex >= 5:
DISPLAY "Just kidding call me The " + user_name;
END IF;
"""
user_input = ex4
...
...
After running the example using our Python script, we see the following results in the terminal:
Error: line 10: Cannot figure out: "END WHILE"
Our current if/else logic will not correctly parse "END WHILE" or "ELSE IF" if they appear in an example pseudocode because it doesn't comprehend those lines. To make the conditional logic simple to apply, we should standardize these minor differences. Add the following to our Python script:
import re
TYPES = {
"integer": "int",
"double": "float",
"float": "float",
"boolean": "bool",
"character": "str",
"string": "str",
}
CONVERTIBLES = [ # <--- NEW
("\t", ""),
("”", '"'),
("MOD", "%"),
("CASE", "case"),
("FALSE", "False"),
("TRUE", "True"),
("false", "False"),
("true", "True"),
("ELSE IF", "ELIF"),
("ELSEIF", "ELIF"),
("ELSIF", "ELIF"),
("END WHILE", "ENDWHILE"),
("END IF", "ENDIF"),
("THEN", ""),
("RANDOM", "random"),
("AND", "and"),
("OR", "or"),
("NOT", "not"),
]
...
...
...
for codeline, line in enumerate(pseudo_no_empty_strings, start=1):
line = re.sub("\s*[;:]\s*$", "", line)
if line.startswith("DECLARE"):
first_word, *args = line.split(",")
var_type, first_var = re_first_construct.match(first_word).groups()
extra_vars = list(map(lambda x: re_remainder.match(x).groups()[0], args))
for var_name in [first_var] + extra_vars:
if var_type.lower() not in TYPES.keys():
print(f"Line {codeline}: Unknown variable type '{var_type}'")
print("Expected variable type in: ", list(TYPES.keys()))
exit(1)
var_types[var_name] = TYPES[var_type.lower()]
for old, new in CONVERTIBLES: # <--- NEW
line = line.replace(old, new)
preprocessed_pseudocode.append(line)
We can try running the full script again. In the terminal,
user_name = "vibes-driven-dev"
first_name = "I"
currentIndex = 0
while currentIndex < 5:
print("My real name is Ifenna and it starts with the letter: ", first_name)
currentIndex = currentIndex + 1
if currentIndex >= 5:
print("Just kidding call me The ", user_name)
The complete Python script:
That worked out nicely. Our script for converting pseudocode to Python code is now complete. We can now build our API to make use of the Python script's functionality. The Django Rest Framework is our preferred API framework, which we introduce in the following section.
Create an API using the Django Rest Framework
In this section, we'll build a basic API for our Python script. Run the following commands in the terminal in a Python managed environment, such as VirtualEnv:
pip install django djangorestframework drf-yasg
django-admin startproject pseudy
cd pseudy
python manage.py startapp api
mkdir common && cd common && echo > pseudopy.py
cd .. && cd api
echo > {serializers,urls}.py # no space between comma
In pseudy/settings.py:
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'drf_yasg',
'api',
]
In pseudy/urls.py
from django.contrib import admin
from django.urls import include, path
from drf_yasg import openapi
from drf_yasg.views import get_schema_view
from rest_framework import permissions
schema_view = get_schema_view(
openapi.Info(
title="Pseudocode to Python Generator API",
default_version='v1',
description="Test description",
terms_of_service="https://www.google.com/policies/terms/",
contact=openapi.Contact(email="contact@summary.haha"),
license=openapi.License(name="BSD License"),
),
public=True,
permission_classes=[permissions.AllowAny],
)
urlpatterns = [
path('admin/', admin.site.urls),
path('docs/', schema_view.with_ui('swagger', cache_timeout=0), name='schema-swagger-ui'),
path('redoc/', schema_view.with_ui('redoc', cache_timeout=0), name='schema-redoc'),
path('', include('api.urls')),
]
In api/models.py:
from django.db import models
class Pseudocode(models.Model):
pseudocode = models.TextField()
python_code = models.TextField(blank=True, null=True)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
In api/serializers.py:
from rest_framework import serializers
from .models import Pseudocode
class PseudoSerializer(serializers.ModelSerializer):
class Meta:
model = Pseudocode
fields = ["pseudocode"]
class PythonSerializer(serializers.ModelSerializer):
class Meta:
model = Pseudocode
fields = ["python_code"]
In api/views.py:
from django.http import HttpResponse
from rest_framework import parsers, status, viewsets
from rest_framework.response import Response
from common.pseudopy import pseudocode_converter
from .models import Pseudocode
from .serializers import PseudoSerializer, PythonSerializer
class PseudoPyViewset(viewsets.ModelViewSet):
queryset = Pseudocode.objects.all()
serializer_class = PseudoSerializer
http_method_names = ["get", "post", "patch"]
parser_classes = [parsers.JSONParser]
def get_serializer_class(self):
if self.action != "create":
return PythonSerializer
return super().get_serializer_class()
def create(self, request):
serializer = PythonSerializer(data=request.data)
if serializer.is_valid(raise_exception=True):
python_code = "\n".join(
pseudocode_converter(request.data.get("pseudocode"))
)
serializer.save(python_code=python_code)
return HttpResponse(
python_code, status=status.HTTP_201_CREATED, content_type="text/plain"
)
return Response(serializer.error_messages, status=status.HTTP_400_BAD_REQUEST)
In common/pseudopy.py:
import re
from django.forms import ValidationError
TYPES = {
"integer": "int",
"double": "float",
"float": "float",
"boolean": "bool",
"character": "str",
"string": "str",
}
CONVERTIBLES = [
("\t", ""),
("”", '"'),
("MOD", "%"),
("CASE", "case"),
("FALSE", "False"),
("TRUE", "True"),
("false", "False"),
("true", "True"),
("ELSE IF", "ELIF"),
("ELSEIF", "ELIF"),
("ELSIF", "ELIF"),
("END WHILE", "ENDWHILE"),
("END IF", "ENDIF"),
("THEN", ""),
("RANDOM", "random"),
("AND", "and"),
("OR", "or"),
("NOT", "not"),
]
re_flags = re.VERBOSE
re_remainder = re.compile(""" \s* ( \w+ )(?: \s* \[ \s* \] )? \s* """, re_flags)
re_first_construct = re.compile(
"""
DECLARE # Start of DECLARE statement
\s* ( \w+ ) # Type
\s+ ( \w+ )(?: \s* \[ \s* \] )? # Variable name
\s* """,
re_flags,
)
def preprocess(user_input: str) -> list: # sourcery skip: raise-specific-error
pseudo_no_empty_strings = list(filter(None, user_input.splitlines()))
var_types: dict = {}
preprocessed_pseudocode = []
for codeline, line in enumerate(pseudo_no_empty_strings, start=1):
line = re.sub("\s*[;:]\s*$", "", line)
if line.startswith("DECLARE"):
first_word, *args = line.split(",")
var_type, first_var = re_first_construct.match(first_word).groups()
extra_vars = list(map(lambda x: re_remainder.match(x).groups()[0], args))
for var_name in [first_var] + extra_vars:
if var_type.lower() not in TYPES.keys():
raise ValidationError(
f"Line {codeline}: Unknown variable type '{var_type}'",
f"Expected variable type in: {list(TYPES.keys())}"
)
var_types[var_name] = TYPES[var_type.lower()]
for old, new in CONVERTIBLES:
line = line.replace(old, new)
preprocessed_pseudocode.append(line)
return preprocessed_pseudocode
def converted(preprocessed_pseudo:list) -> list:
output = ""
while_level = 0
if_level = 0
converted_psuedocode = []
for codeline, line in enumerate(preprocessed_pseudo, start=1):
indent_level = while_level + if_level
if (
line.startswith("DECLARE")
or line.startswith("PROGRAM")
or line.startswith("START")
or line.startswith("BEGIN")
):
output = ""
elif line.startswith("DISPLAY"):
line = re.sub("DISPLAY ?", "print(", line).strip() + ")"
line = re.sub('("[^"]*?")\s*\+\s*', "\\1, ", line) # removes "+"
output = re.sub('\s*\+\s*("[^"]*?")', ", \\1", line)
elif line.startswith("SET"):
output = line.replace("SET", "").strip()
elif line.startswith("WHILE"):
while_level += 1
output = line.replace("WHILE", "while").strip() + ":"
elif line.startswith("IF"):
if_level += 1
output = line.replace("IF", "if").strip() + ":"
elif line.startswith("ENDIF"):
if if_level == 0:
raise IndentationError(f"line {codeline}: no IF block for ENDIF.")
if_level -= 1
output = ""
elif line.startswith("ENDWHILE"):
if while_level == 0:
raise IndentationError(f"line {codeline}: no WHILE block for ENDWHILE.")
output = ""
while_level -= 1
elif line.startswith("ELSE"):
if if_level == 0:
raise IndentationError(f"line {codeline}: no IF block for ELSE.")
output = "else:"
indent_level -= 1
elif line.startswith("ELIF"):
if if_level == 0:
raise IndentationError(f"line {codeline}: no IF block for ELSEIF.")
output = line.replace("ELIF", "elif").strip() + ":"
indent_level -= 1
else:
raise ValidationError(f'Error: line {codeline}: Cannot figure out: "{line.strip()}"')
indentation = indent_level * " "
if not isinstance(output, list):
output = [output]
converted_psuedocode.extend(
indentation + python_line for python_line in output if python_line != ""
)
return converted_psuedocode
def pseudocode_converter(user_input: str) -> list:
"""Return a list of converted Pseudocode in Python"""
preprocessed = preprocess(user_input)
return converted(preprocessed)
In terminal run:
python manage.py makemigrations
python manage.py migrate
python manage.py runserver
Visit the interactive doc (OpenAPI) at http://localhost:8000/docs. Visit the Django Rest Framework browser API at http://localhost:8000/
Testing our API
We can test the OpenAPI interactive API implementation.
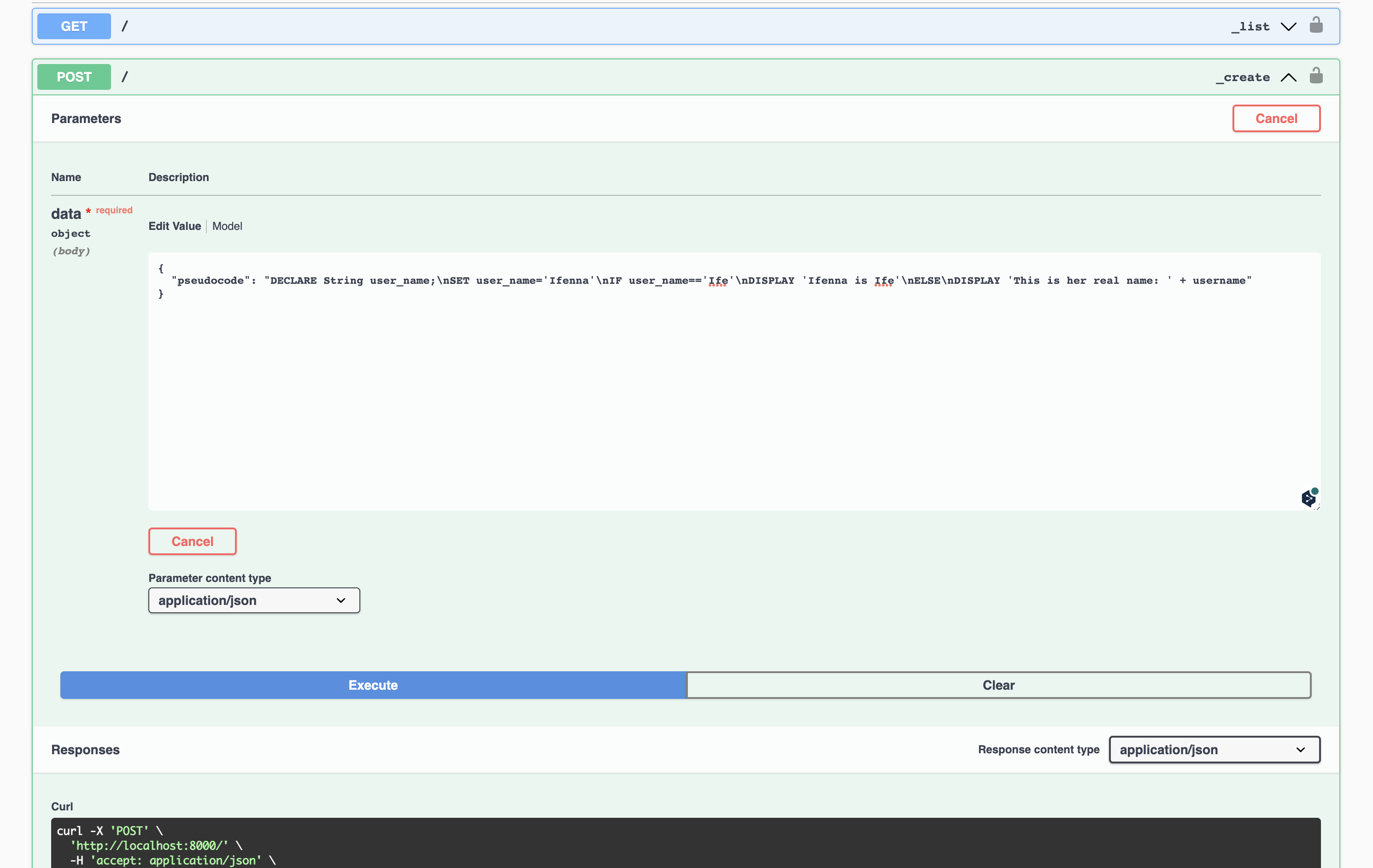
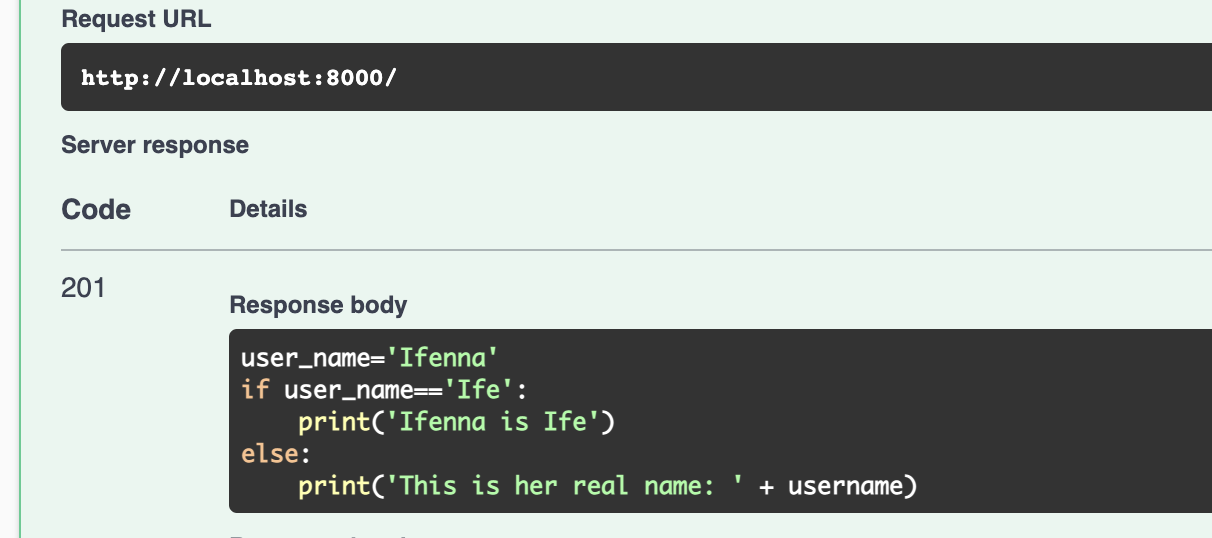
As we can see, our API performs as intended. We could make our pseudopy.py file more pythonic by breaking the large function down into smaller functions. Additionally, we could expand the functionality of our Python generator API to include support for objects, dictionaries, and arrays/lists.
We might also think about creating a nice frontend for the API that interacts with it. This tutorial project is open for improvement.
DECLARE Function Outro()
In this article, we demonstrated how to build a tool that can translate pseudocode into Python executable code using regular expressions and a little string manipulation. The Django Rest Framework allowed us to transform this script for converting pseudocode into an API.
Why did I write this article on how to create a script that converts Pseudocode to Python? It just seems like one of those projects that might seem very simple at first, but can have its own twist, as you may have seen in this article.
Aside from that, some people may simply prefer to see pseudocode from algorithm books written in their preferred language, in this case Python. So why not make a project out of it? And, as usual, I didn't want to publish an article that creates a todo list.
You have our sincere goodbyes until the next time, Laptop and this Lady👩🏾💻.



