

Build a Text Summarizer API using Django Rest Framework and spaCy
A text-summarizing rest API tool created using spaCy and the Django Rest Framework. A weekend project suitable for beginners and intermediates.

"Not another todo app"
~ Super Laptop and the AI Lady
In this article, we'll demonstrate how to create a concise text-summarizing app. You are not required to have any prior knowledge of natural language processing (in this context). Simply put, we want to create something that isn't a to-do app. The Github repository for this project is available here. Let's get started!🚀
In the terminal,
pip install django djangorestframework
django-admin startproject iSummary
cd iSummary
Create and activate a virtual environment for the project.
python -m venv venv
source venv/bin/activate
Text Summarizer with spaCy
Make a common folder in the root. This will include every NLP-related function that was used to develop the text-summary API. We create a new file called summarizer.py.
mkdir common && cd common && echo > summarizer.py
The English dataset from spaCy will be installed here. en_core_web_sm is the name of a small dataset that is only 12 MB in size. SpaCy needs to be installed first.
pip install -U spacy
To download the trained pipeline, run:
python -m spacy download en_core_web_sm
There are a few options available here. We could learn more about named entities, nouns, stopwords, and other terms used in natural language processing, but since this is a project for software engineers, we won't get too specific. However, let me know if you'd like content on NLP!
In your common/summarizer.py add:
There is a lot going on in the code above. We tokenize the document first. In other words, we decode sentences into words. In essence, the get_frequency_distribution() method determines how often each word appears. We are aware that the English language makes extensive use of prepositions, articles, pronouns, and punctuation. We take out all of the unnecessary English words and score each word according to its frequency in the function.
These are referred to as "noise" in NLP because sentences without these English words still make sense. An illustration would be "Okoye, the old man, ran like a dog was chasing him around". We have "Okoye old man ran like dog chasing around" if we remove some of the noise. Even though this sentence lacks punctuation and some articles, it is clear that Okoye fled because of a dog.
Similar to get_frequency_distribution(), get_sentences_score() scores sentences based on the number of words that are present and aren't stopwords or punctuation.
The get_top_sentences() gets the top sentences based on the heap algorithm to find the largest elements in a dataset.
Django Rest Framework API
Let's build a simple crud API that makes use of the summarizer functions now that they have been completed.
cd .. # <--- change directory from the "common" folder back to "iSummary"
python manage.py startproject gege
We update our INSTALLED_APPS in iSummary/settings.py:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'gege',
]
In models.py:
from django.db import models
class TextSummary(models.Model):
title = models.CharField(max_length=100, blank=True, null=True)
original_text = models.TextField()
summarized_text = models.TextField()
created_at = models.DateField(auto_now_add=True)
updated_at = models.DateField(auto_now=True)
def __str__(self) -> str:
return self.title or self.original_text[:3]
In admin.py:
from django.contrib import admin
from .models import TextSummary
admin.sites.register(TextSummary)
Create our Django Rest Framework serializer in gege/serializers.py:
from rest_framework import serializers
from .models import TextSummary
class OriginalTextSerializer(serializers.ModelSerializer):
class Meta:
model = TextSummary
exclude = ["summarized_text"]
def create(self, validated_data):
try:
# if user provides the length they want their summary
# make sure remove it since the information is not used
# in TextSummary Model.
# If we don't remove it, DRF will raise an error that the field does not exist.
validated_data.pop("summary_sentence_length")
except Exception:
# if the field is not there then do nothing.
...
TextSummary.objects.create(**validated_data)
return validated_data
class TextSummarySerializer(serializers.ModelSerializer):
class Meta:
model = TextSummary
field = "__all__"
Add the following in the gege/views.py:
from rest_framework import viewsets
from .serializers import OriginalTextSerializer, TextSummarySerializer
from .models import TextSummary
class SummarizerViewset(viewsets.ModelViewSet):
queryset = TextSummary.objects.all()
serializer_class = TextSummarySerializer
http_method_names = ["get", "post", "patch", "delete"]
def get_serializer_class(self):
if self.action == "create":
return OriginalTextSerializer
return super().get_serializer_class()
Create gege/urls.py and add the following:
from rest_framework import routers
from .views import SummarizerViewset
router = routers.SimpleRouter()
router.register("", SummarizerViewset)
urlpatterns = router.urls
In the root URL (iSummary/urls.py), include our Gege app:
from django.contrib import admin
from django.urls import path, include # new
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('gege.urls')), # new
]
Let's migrate our sqlite database, create an admin user and start the server.
python manage.py makemigrations
python manage.py migrate
python manage.py createsuperuser --username admin --email admin@gmail.com
python manage.py runserver
We can visit http://localhost:8000/.
Integrating text summarizer with Django Rest Framework API
The Summary class we previously created in the summary.py file located in the common folder can now be included in our SummaryViewset.
For this, as shown in the code snippet below, we can update the create method in the SummaryViewset to summarize the text and add it to our database.
from rest_framework import viewsets, status
from rest_framework.response import Response
from .serializers import OriginalTextSerializer, TextSummarySerializer
from .models import TextSummary
from common.summarizer import Summarizer
class SummarizerViewset(viewsets.ModelViewSet):
queryset = TextSummary.objects.all()
serializer_class = TextSummarySerializer
http_method_names = ["get", "post", "patch", "delete"]
def get_serializer_class(self):
if self.action == "create":
return OriginalTextSerializer
return super().get_serializer_class()
def create(self, request):
serializer = OriginalTextSerializer(data=request.data)
if serializer.is_valid(raise_exception=True):
# if no error is raised by our serializer
# create an instance of the Summarizer tool
try:
summary_length = int(request.data.get("summary_sentence_length")) or None
except Exception:
summary_length = None
summarizer = Summarizer(request.data.get("original_text"), summary_length)
summary = summarizer.get_summary()
serializer.save(summarized_text=summary)
return Response({
"detail": "Success",
"summary": summary
})
return Response(serializer.error_messages, status=status.HTTP_400_BAD_REQUEST)
The user will receive the shortened text back.
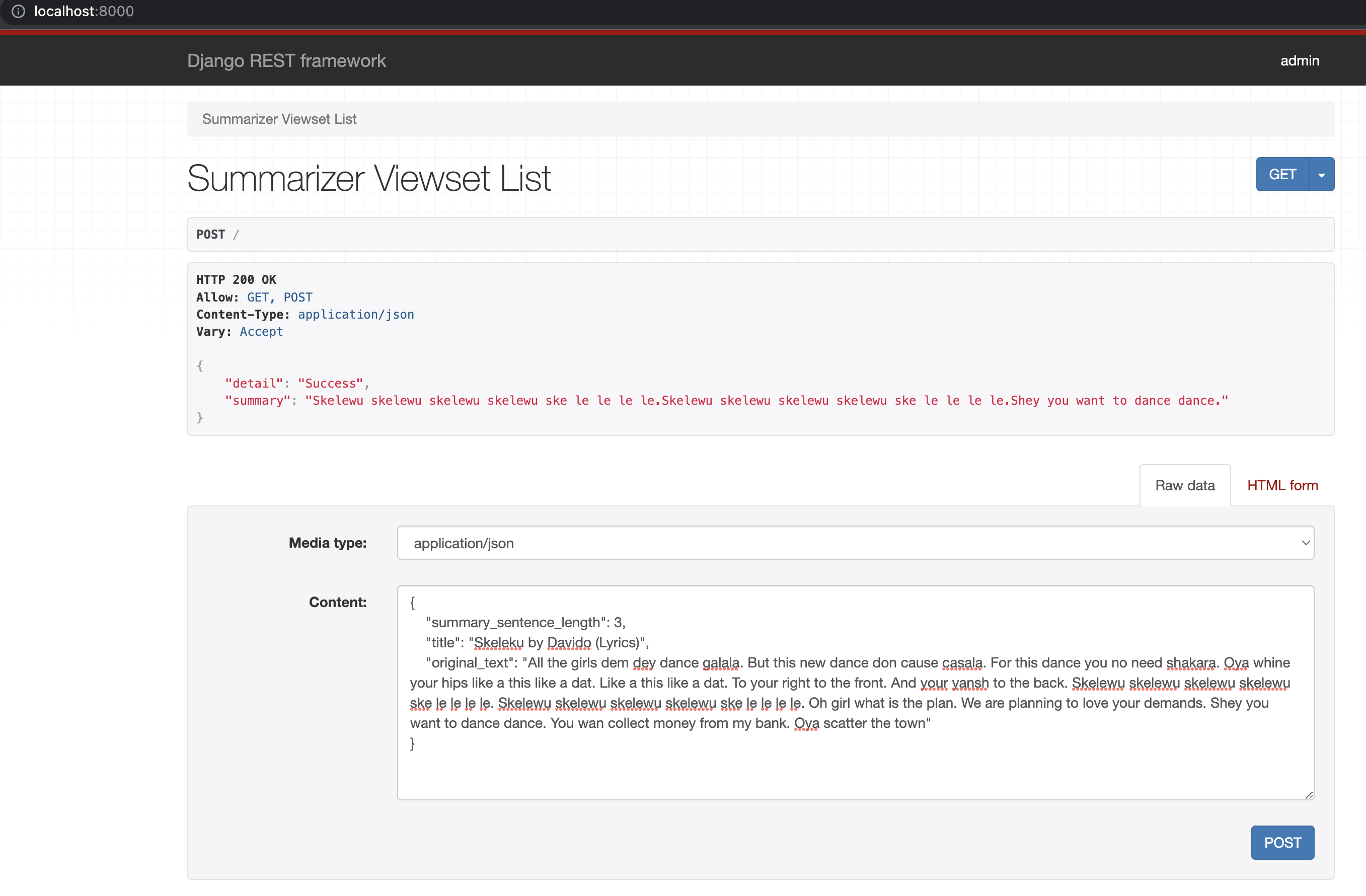
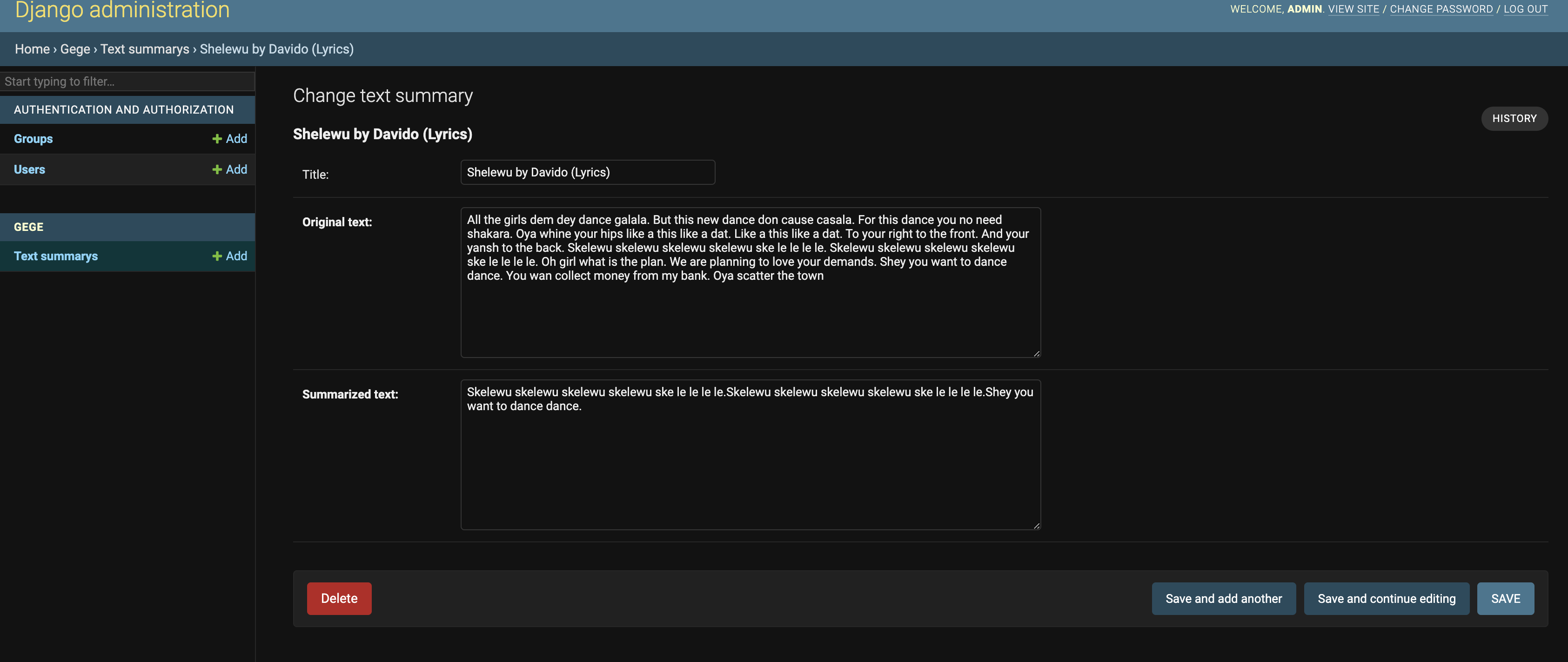
Additionally, we have access to the data stored in the database.
Now that the API is operational. Let's add some documentation.
Using OpenAPI (Swagger) for Documentation.
For other people to be able to use our APIs, we must document them. We can document our APIs using the excellent OpenAPI specification. More information on OpenAPI is available at https://swagger.io/specification.
We'll use [drf-yasg] (https://github.com/axnsan12/drf-yasg) to generate our Swagger documentation.
pip install -U drf-yasg
In settings.py, add:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'drf_yasg', # NEW
'rest_framework',
'gege',
]
In iSummary/urls.py:
from django.contrib import admin
from django.urls import include, path
from drf_yasg import openapi
from drf_yasg.views import get_schema_view
from rest_framework import permissions
schema_view = get_schema_view(
openapi.Info(
title="Text Summarizer API",
default_version='v1',
description="Test description",
terms_of_service="https://www.google.com/policies/terms/",
contact=openapi.Contact(email="contact@summary.haha"),
license=openapi.License(name="BSD License"),
),
public=True,
permission_classes=[permissions.AllowAny],
)
urlpatterns = [
path('admin/', admin.site.urls),
path('docs/', schema_view.with_ui('swagger', cache_timeout=0), name='schema-swagger-ui'),
path('redoc/', schema_view.with_ui('redoc', cache_timeout=0), name='schema-redoc'),
path('', include('gege.urls')),
]
It performs an automatic search of all the Django app's endpoints and generates a fancy documentation that is accessible at http://localhost:8000/docs/.
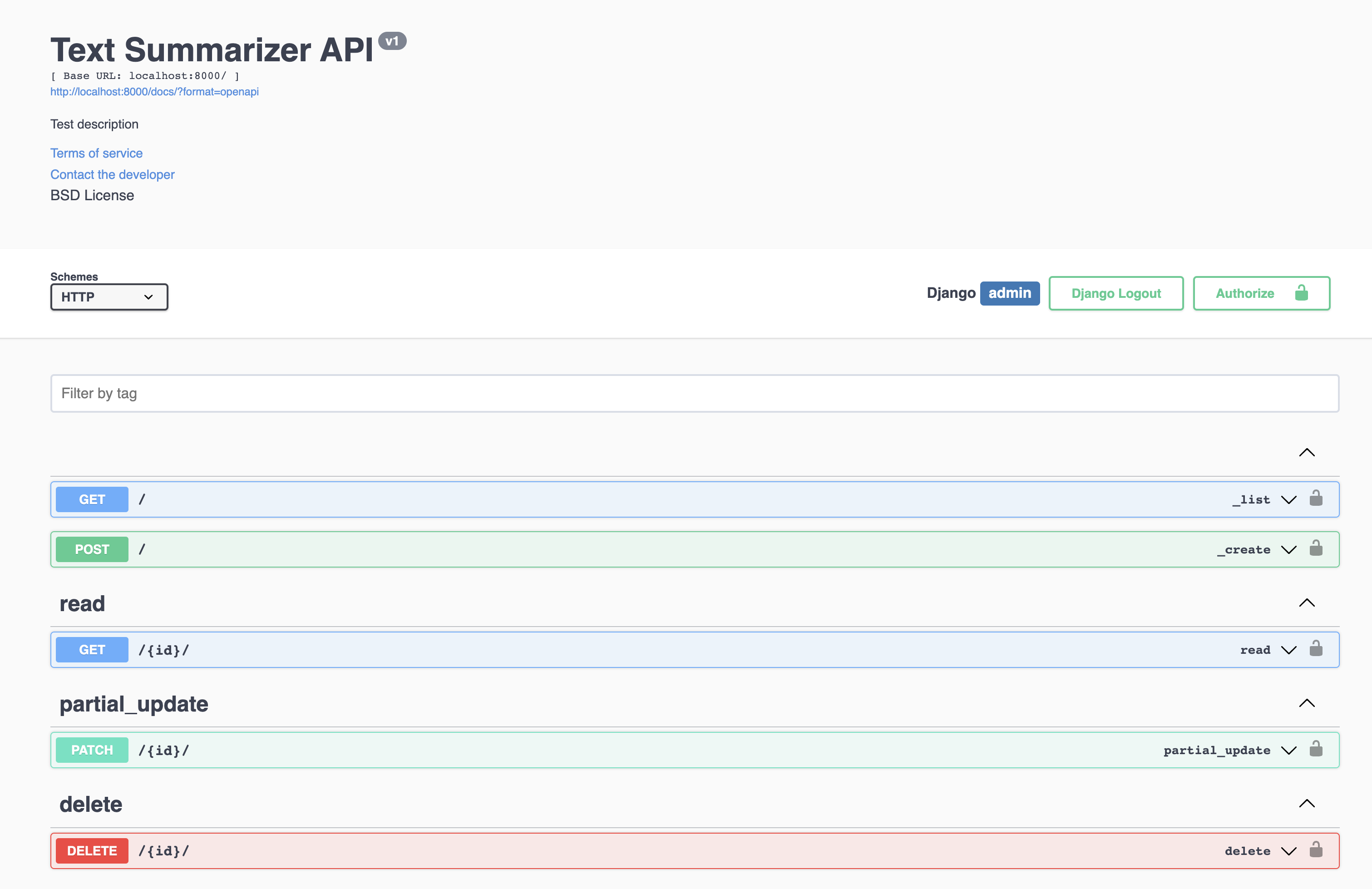
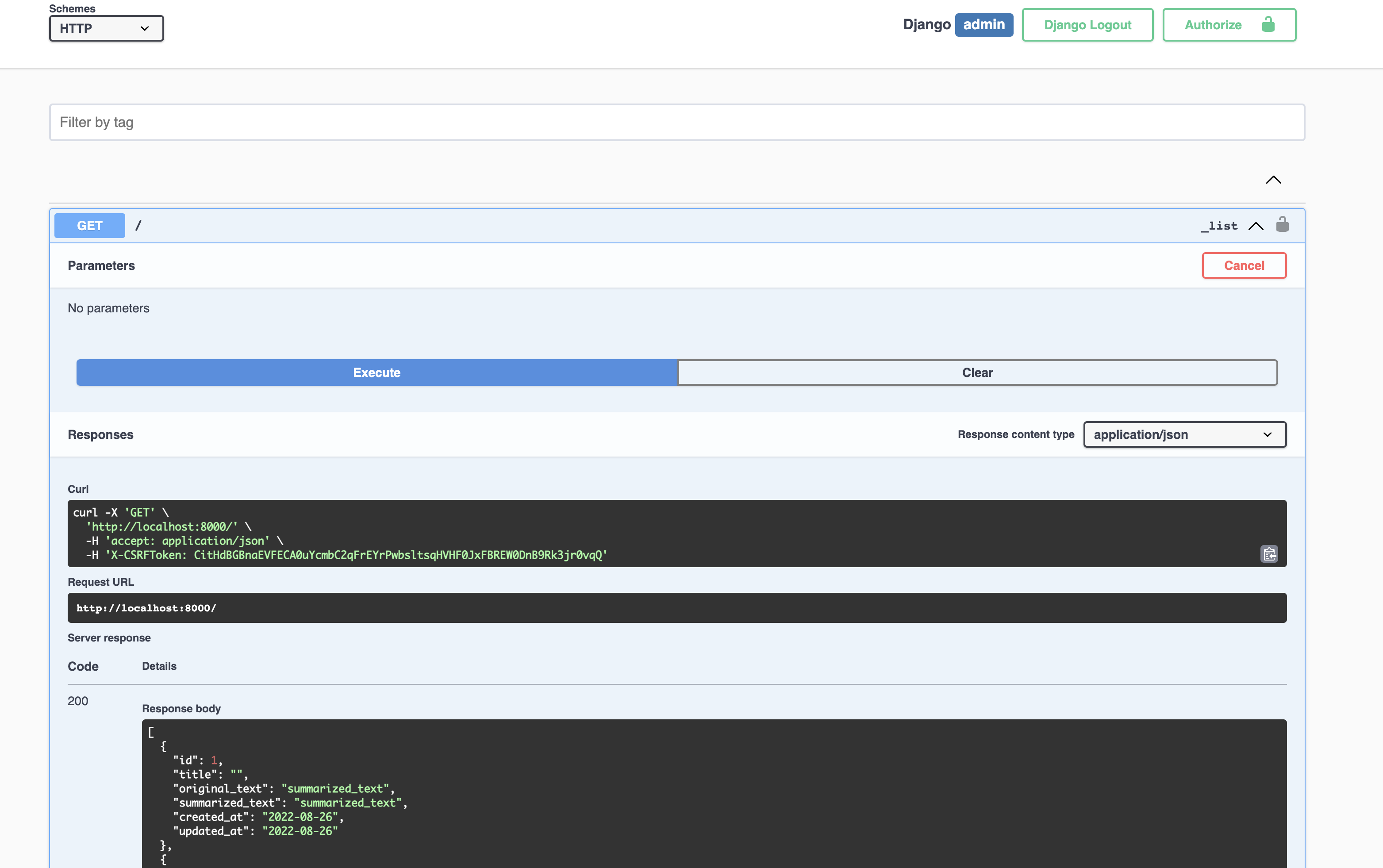
There is no written documentation about what each endpoint will do; instead, there is an interactive API that shows the schemas to use.
The Redoc generated documentation version can be found at http://localhost:8000/redoc/
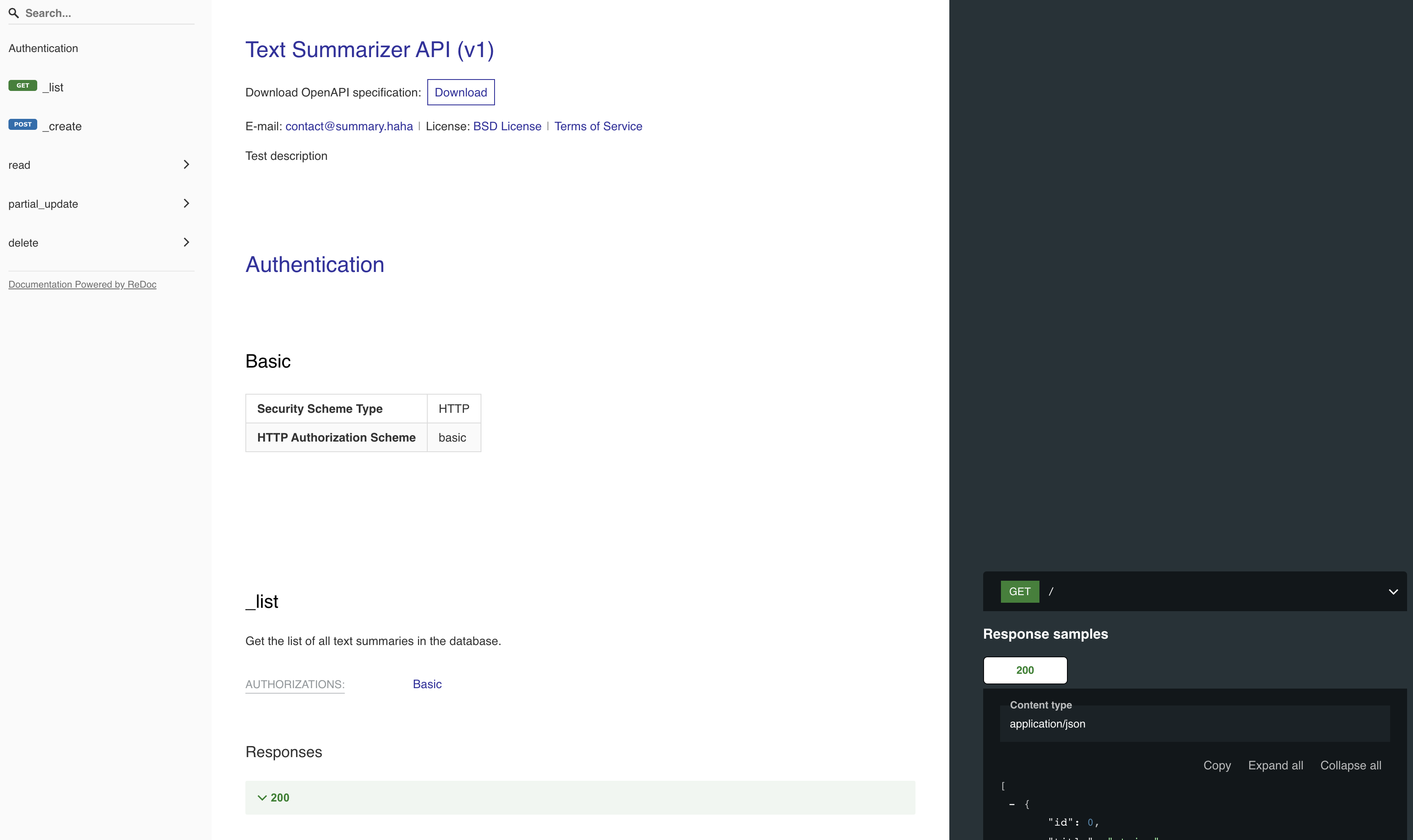
We can add proper documentation by updating the views' Python docstring. The information in the docstring will be used as written documentation on how to use the endpoint.
class SummarizerViewset(viewsets.ModelViewSet):
"""
create: Create a new text summary based on the original text.
`Optional`: Include how many sentences you would like the summary to contain.
list: Get the list of all text summaries in the database.
partial_update: Update a part of the data such as the summary, original text or title.
destroy: Delete a summary by ID.
retrieve: Retrieve a summary by ID
"""
queryset = TextSummary.objects.all()
...
Let's reload the documentation now.
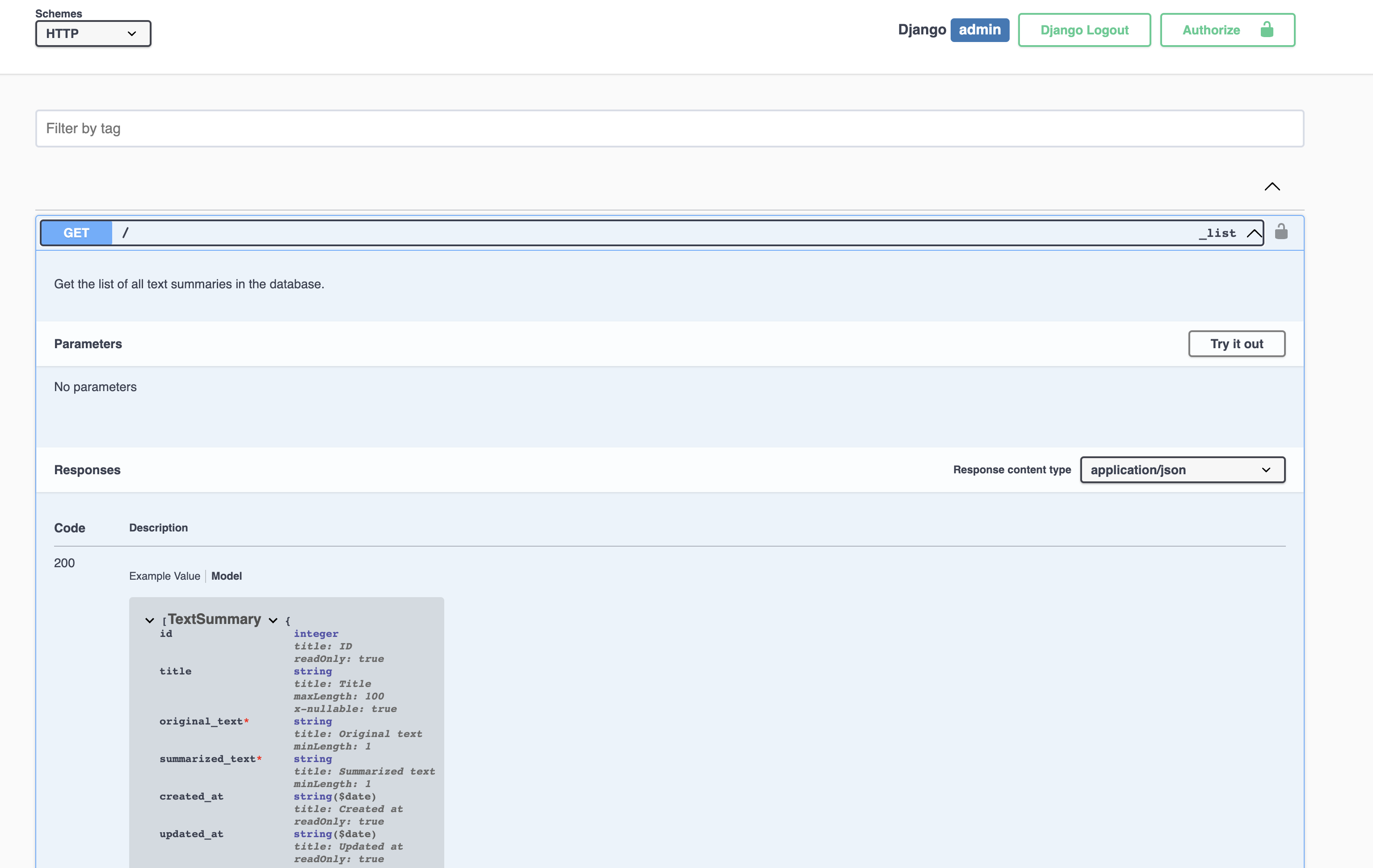
You are free to experiment. This is the fundamentals of using drf-yasg. There are more advanced applications for this tool.
Summary
In this article, we used the heap algorithm and spaCy to create a straightforward Django Rest Framework API for text summarization. In order to document APIs using the OpenAPI (Swagger) specification, we used drf-yasg.
The idea for this article was to come up with a fun project that could be finished in an afternoon without having to get too technical and just enjoy feeling smart. Without going into the mathematical nitty-gritty, I hope I was able to pique your interest in Machine Learning (Natural Language Processing).
That said, this Laptop and Lady shall bid you farewell.




